- [알고리즘] 퀵 정렬2023년 12월 25일 09시 58분 03초에 업로드 된 글입니다.작성자: 민발자728x90

퀵 정렬
기준값 pivot을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘
기준값이 어떻게 선정되는지가 시간복잡도에 많은 영향을 미치고 평균 시간복잡도는 O(nlogn)이며 최악의 경우 O(n^2)
퀵 정렬 과정
기준값을 중심으로 계속 데이터를 2개의 집합으로 나누면서 정렬하는 것이 핵심
쿽 정렬의 시간 복잡도는 비교적 준수한 편
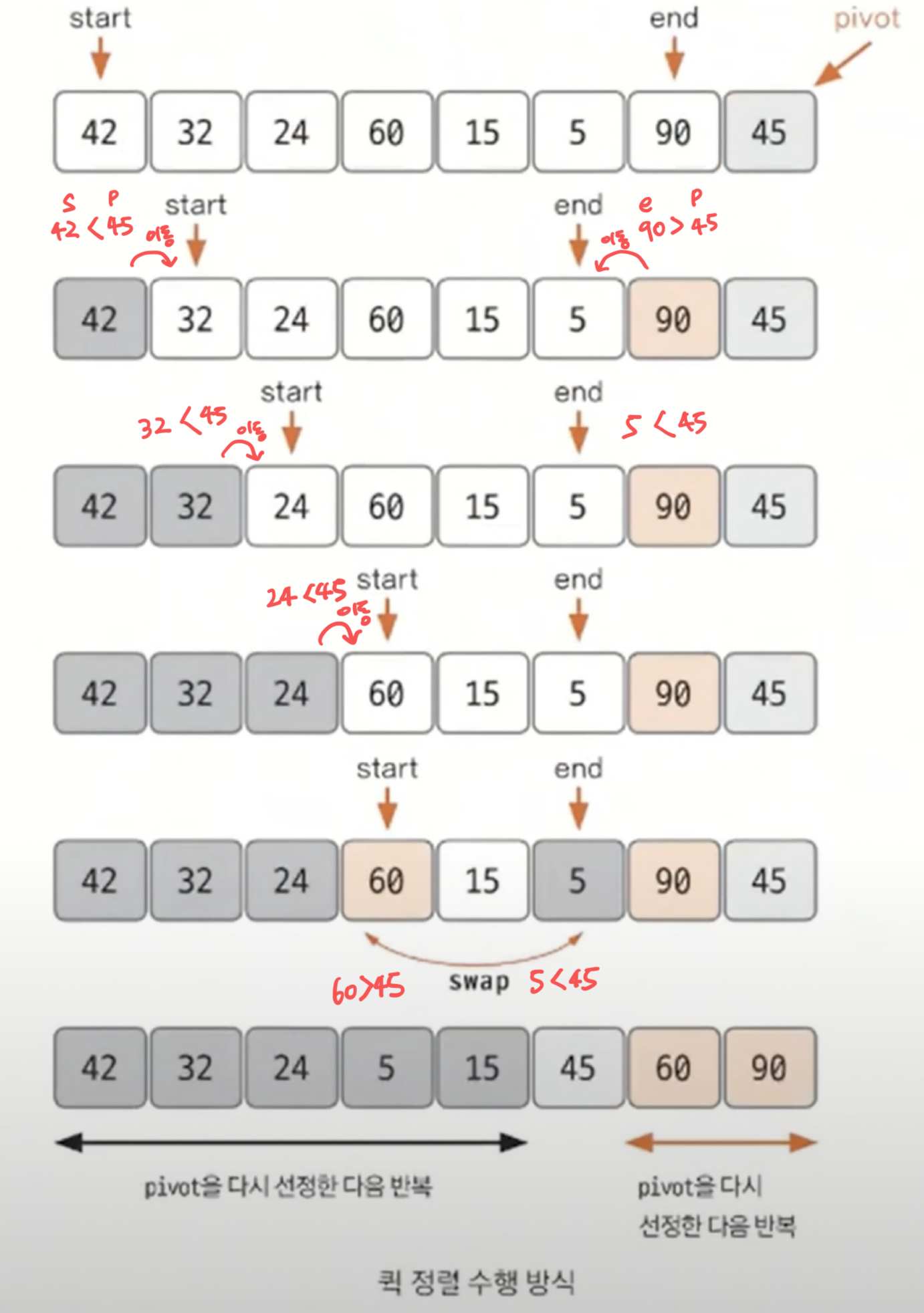
- 데이터를 분할하는 pivot을 설정
- pivot을 기준으로 데이터를 2개의 집합으로 분리
- start가 pivot보다 작으면 start를 오른쪽으로 1칸 이동
- end가 pivot보다 크면 end를 왼쪽으로 1칸 이동
- start가 pivot보다 크고, end가 pivot보다 작으면 start, end 데이터를 swap하고 start는 오른쪽, end는 왼쪽으로 1칸 이동
- start와 end가 만날 때까지 반복
- start와 end가 만나면 만난 지점 데이터와 pivot을 비교하며 pivot이 크면 만난 지점 오른쪽에, 작으면 만난 지점 왼쪽에 pivot 삽입
- 분리 집합에서 각각 다시 pivot 선정
- 분리 집합이 1개 이하가 될 때까지 과정 반복
728x90'공부 > 알고리즘' 카테고리의 다른 글
[알고리즘] BFS 너비 우선 탐색 (0) 2023.12.27 [알고리즘] DFS 깊이 우선 탐색 (2) 2023.12.26 [알고리즘] 삽입 정렬 (0) 2023.12.23 [알고리즘] 선택정렬 (0) 2023.12.23 [알고리즘] 버블정렬 (0) 2023.12.23 이전글이 없습니다.댓글