

ch 11-30~33 Comparator와 Comparable
1. Comparator와 Comparable
객체 정렬에 필요한 메서드(정렬기준 제공)를 정의한 인터페이스
Comparator : 기본 정렬기준을 구현할 때 사용
public interface Comparator {
int compare(Object o1, Object o2); // o1과 o2 두 객체를 비교, 0 o1=o2 양수 o1>o2, 음수 o1<o2
boolean equals(Object obj); // equals 오버라이딩
}Comparable : 기본 정렬기준 외 다른 기준으로 정렬하고자 할 때 사용
public interface Comparable {
int compareTo(Object o); // 주어진 객체 o와 자신this을 비교
}sort() : 두 대상을 비교해 자리바꿈
정렬 기준을 정해줄 때 사용하는 것이 Comparator, Comparable
2. compare(), CompareTo()
두 객체의 비교결과를 반환
같으면 0, 오른쪽이 크면 음수, 오른쪽이 작으면 양수
3. String의 정렬
정렬 : 대상과 기준이 필요
sort(Object[] a) → 기준이 없지만, 지정된 객체가 가지고 있는 Comparable에 의해 기준 제공되어 정렬됨
CASE_INTENSITIVE_ORDER : String의 Comparator, 대소문자 구분 안 함
class Ex11_7 {
public static void main(String[] args) {
String[] strArr = {"cat", "Dog", "lion", "tiger"};
Arrays.sort(strArr); // String의 Comparable구현에 의한 정렬
// String 클래스에 compareTo()에 의해 기준이 제공
System.out.println("strArr=" + Arrays.toString(strArr));
Arrays.sort(strArr, String.CASE_INSENSITIVE_ORDER); // 대소문자 구분 안함
// String 클래스에 있는 정렬기준
System.out.println("strArr=" + Arrays.toString(strArr));
Arrays.sort(strArr, new Descending()); // 역순정렬
// 직접 정의해서 사용
System.out.println("Descending strArr=" + Arrays.toString(strArr));
}
}
class Descending implements Comparator {
public int compare(Object o1, Object o2){
if( o1 instanceof Comparable && o2 instanceof Comparable) {
Comparable c1 = (Comparable)o1;
Comparable c2 = (Comparable)o2;
return c1.compareTo(c2) * -1 ; // -1을 곱해서 기본 정렬방식의 역으로 변경
// 또는 c2.compareTo(c1)와 같이 순서를 바꿔도 동일 결과
}
return -1;
}
}
4. Integer와 Comparable
sort() 수행하는 과정에서 compareTo() 호출해서 반환 값에 의해 자리바꿈
ch 11-34~36 HashSet(1)
1. HashSet
순서 없고 중복 불가
Set인터페이스를 구현한 대표적인 컬렉션 클래스
LinkedHashSet : 순서 유지
TreeSet : 범위 검색과 정렬에 유리한 컬렉션 클래스, 데이터 추가, 삭제에 시간 오래 걸림
| 생성자 또는 메서드 | 내용 |
| HashSet() | 생성자 |
| HashSet(Collection c) | 생성자 |
| HashSet(int initialCapacity) | 초기용량 |
| HashSet(int initialCapacitym float loadFactor) | 초기용량 설정 후 loadFctor만큼 차면 용량 2배로 늘림 |
| boolean add(Object o) | 추가 |
| boolean addAll(Collection c) | 모두 추가, 합집합 |
| boolean remove(Object o) | 객체o 삭제 |
| boolean removeAll(Collection c) | c에 있는 여러 객체들 삭제, 차집합 |
| boolean retainAll(Collection c) | 조건부 삭제, 교집합, c에 있는 것만 제외하고 삭제 |
| void clear() | 모두 삭제 |
| boolean contains(Object o) | 객체o 포함 확인 |
| boolean containsAll(Collection c) | c 여러 객체 포함 확인 |
| Iterator iterrator() | 컬렉션 요소 읽기 |
| boolean isEmpty() | 비어있는지 확인 |
| int size() | 저장된 객체의 갯수 |
| Object[] toArray() | 저장되어 있는 객체 array로 반환 |
| Object[] toArray(Object[] a) | 저장되어 있는 객체 array로 반환 |
ch 11-37~38 HashSet(2)
1. add(Object o)
객체를 저장하기 전에 기존에 같은 객체가 있는지 확인
add메서드 호출하면 저장할 객체를 비교하기 위해 equals()와 hashCode()를 호출
equals() hashCode()가 오버라이딩 되어있지 않으면 비교작업이 제대로 동작하지 않음
class Ex11_11 {
public static void main(String[] args) {
HashSet set = new HashSet();
set.add("abc");
set.add("abc"); // 중복이라 저장안됨
set.add(new Person("David",10));
set.add(new Person("David",10));
// 중복인데 저장됨 -> equlas(), hashCode() 오버라이딩 안함
System.out.println(set);
}
}
// equals(), hashCode() 오버라이딩해야 HashSet 바르게 동작
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return name +":"+ age;
}
// 오버라이딩
@Override
public int hashCode() {
return Objects.hash(age, name);
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
if(!(obj instanceof Person))
return false;
Person p = (Person) obj;
return age == p.age && Objects.equals(name, p.name);
}
}
2. 차집합, 교집합, 합집합 구현하기
// 교집합
Iterator it = setB.iterator();
while(it.hasNext()) {
Object tmp = it.next(); // B를 하나씩 꺼내옴
if(setA.contains(tmp)) // setA에 B가 있는지 확인 true만 저장
setKyo.add(tmp);
}
// 합집합 a+b
it = setA.iterator();
while(it.hasNext())
setHab.add(it.next());
it = setB.iterator();
while(it.hasNext())
setHab.add(it.next());
// 차집합 a-b
it = setA.iterator();
while(it.hasNext()) {
Object tmp = it.next(); // A를 하나씩 꺼내옴
if(!setB.contains(tmp)) // setB에 A가 있는지 확인해서 false만(B에 없는것만) 저장
setCha.add(tmp);
}
3. 차집합, 교집합, 합집합 간단하게 메서드로 구현
// 교집합 retainAll
setA.retainAll(setB);
// 합집합 addAll
setA.addAll(setB); // 중복 제외하고 B모두 저장
// 차집합 removeAll
setA.removeAll(setB);ch 11-39~41 TreeSet(1)
1. TreeSet
이진 탐색 트리로 구현, 범위탐색(from~to), 정렬에 유리
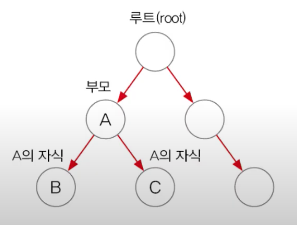
이진트리 binary tree : 모든 노드가 최대 2개의 하위 노드를 가짐
각 요소가 나무 형태로 연결(LinkedList의 변형)
트리노드 TreeNode : 연결되어 있는 요소 의미, 왼쪽 자식노드, 저장할 객체, 오른쪽 자식노드로 구성
class TreeNode {
TreeNode left; // 왼쪽 자식 노드
Object element; // 저장할 객체
TreeNode right; // 오른쪽 자식 노드
}
2. 이진 탐색 트리 binary search tree
부모보다 작은 값은 왼쪽, 큰 값은 오른쪽에 저장
데이터가 많아질수록 추가, 삭제 시간이 오래 걸림(비교 횟수 증가로 인해)
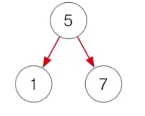
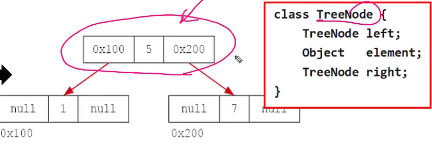
3. TreeSet
boolean add(Object o) : 데이터 저장, compare() 호출해서 비교해서 저장
루트부터 트리를 따라 내려가며 값을 비교해 저장, 작으면 왼, 크면 오른쪽 저장
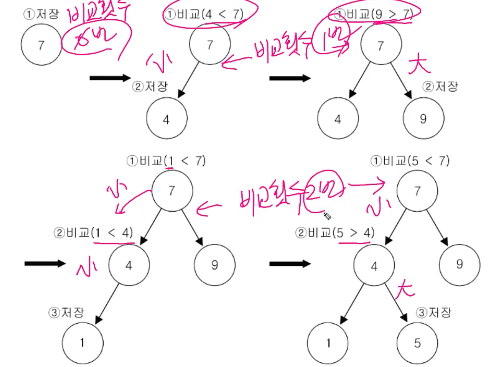
ch 11-42~45 TreeSet(2)
1. 생성자와 주요 메서드
add, remove, size, isEmpty, iterator 등 Collection 인터페이스에서 가지고 있는 메서드도 있음
| 생성자 또는 메서드 | 설명 |
| TreeSet() | 기본 생성자, 정렬기준은 comparable로 비교기준 제공 |
| TreeSet(Collection c) | 주어진 컬렉션 c를 저장하는 TreeSet 생성 |
| TreeSet(Comparator comp) | 주어진 정렬기준 comp로 정렬하는 TreeSet 생성 |
| Object first() | 정렬된 순서에서 첫 번째 객체 반환 |
| Object last() | 정렬된 순서에서 마지막 객체 반환 |
| Object ceiling(Object o) | o와 같은 객체, 없으면 큰 값을 가진 객체 중 제일 가까운 값 객체 반환, 없으면 null |
| Object floor(Object o) | o와 같은 객체, 없으면 작은 값을 가진 객체 중 제일 가까운 값 객체 반환, 없으면 null |
| Object higher(Object o) | o보다 큰 값을 가진 객체 중 가까운 값의 객체 반환, 없으면 null |
| Object lower(Object o) | o보다 작은 값을 가진 객체 중 가까운 값의 객체 반환, 없으면 null |
| SortedSet subSet(Object fromElement, Object toElement) | 범위 검색(from~to)의 결과를 반환, toElement는 포함X |
| Sorted headSet(Object toElement) | 지정 객체보다 작은 값 객체 반환 |
| SortedSet tailSet(Object fromElement) | 지정 객체보다 큰 값 객체 반환 |
class Ex11_13 {
public static void main(String[] args) {
Set treeSet = new TreeSet(); // 정렬되어 정렬 필요없음
Set hashSet = new HashSet(); // 정렬 필요
Set treeSetComp = new TreeSet(new TestComp()); // 정렬 기준 넣어서 생성
Set treeSetComparable = new TreeSet();
for (int i = 0; treeSet.size() < 6 ; i++) {
int num = (int)(Math.random()*45) + 1;
treeSet.add(num);
// set.add(new Integer(num)); Integer에 정렬기준 comparable이 있어 오류 안남
hashSet.add(num); // 정렬 안됨
treeSetComp.add(new Test()); // 정렬기준이 없어 에러발생
treeSetComparable.add(new Test2()); // 저장 객체가 comparable 비교 기준을 가지고 있어 정렬되어 저장
}
System.out.println("treeSet: " + treeSet);
System.out.println("hashSet: " + hashSet);
System.out.println("treeSetComp: " + treeSetComp);
System.out.println("treeSetComparable: " + treeSetComparable);
}
}
class Test{} // 비교기준이 없음
class TestComp implements Comparator { // 정렬기준 만들어줌
@Override
public int compare(Object o1, Object o2) {
return 1;
}
}
class Test2 implements Comparable{
@Override
public int compareTo(Object o) {
return -1;
}
}
2. 범위검색 subSet(), headSet(), tailSet()
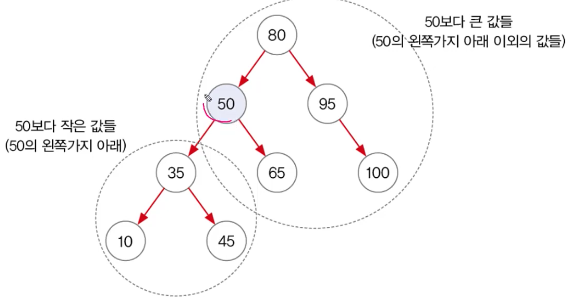
3. 트리순회 tree traversal
이진트리의 모든 노드를 한 번씩 읽는 것
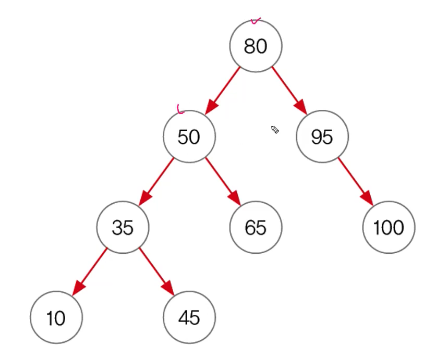
전위순회 preorder : 부모먼저 자식
후위순회 postorder : 부모를 나중에
레벨순회 levelorder : 한 층씩
중위순회 inorder : 부모를 가운데 왼→부모→오른쪽 자식, 오름차순으로 정렬됨 10→35→45→50→65→80→95→100
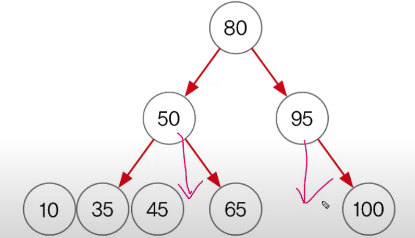
ch 11-46~47 HashMap(1)
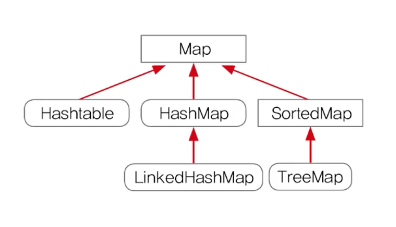
1. HashMap과 HashTable
순서 없고, 중복(키X, 값O)
Map 인터페이스를 구현, 데이터를 키와 값의 쌍으로 저장
HashMap 동기화X, 신버전
HashTable 동기화O, 구버전
TreeMap : TreeSet과 같은 특성, 이진탐색트리, 범위검색과 정렬에 유리, HashMap보다 데이터 추가,삭제에 많은 시간 필요
2. HashMap
Map 인터페이스를 구현한 대표적 컬렉션 클래스
순서필요하면 LinkedHashMap 클래스 사용
3. HashMap의 키와 값
해싱기법으로 데이터 저장, 데이터 많아도 검색이 빠름
키 key : 컬렉션 내의 키 중 유일해야함
값 value : 키와 달리 데이터 중복 허용
HashMap map = new HashMap();
map.put("id", "123");
map.put("asd", "111");
map.put("asd", "456");
/*
출력결과
id 123
asd 456
asd키 중복불가로 값이 111저장되었다가 456으로
*/
4. 해싱 hashing
해시함수를 이용해 해시테이블hash table에 데이터를 저장하고 검색
키를 넣으면 해시코드(배열 index) 반환
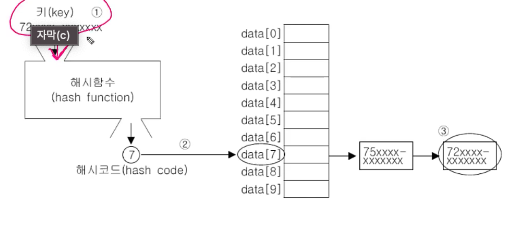
해시테이블 : 배열과 LinkedList가 조합된 상태
→ 배열은 접근성이 좋고, 링크드리스트는 변경에 유리한 것을 섞음 해시코드(index)를 통해 빠르게 검색가능, 링크드리스트 장점 통해 변경에 유리하게 함
5. 해시테이블에서 데이터 검색 방법
①키로 해시함수 호출해 해시코드 얻음
②해시코드에 대응하는 링크드리스트를 배열에서 찾음
③링크드리스트에서 키와 일치하는 데이터 찾음
→ 해시함수는 같은 키에 대해 항상 같은 해시코드를 반환, 서로 다른 키라도 같은 값의 해시코드 반환할 수도 있음
ch 11-48~51 HashMap(2)
1. HashMap의 주요 메서드
| 생서자 또는 메서드 | 설명 |
| HashMap() | 기본 생성자 |
| HashMap(int initialCapacity) | 배열 초기용량지정 |
| HashMap(int initialCapacity, float loadFactor) | 초기용량 설정 후 loadFctor만큼 차면 용량 2배로 늘림 |
| HashMap(Map m) | m을 HashMapd으로 변경 |
| Object put(Object key, Object value) | 데이터 저장 |
| void putAll(Map m) | 지정된 m에 있는 객체 모두 저장 |
| Object remove(Object key) | 지정된 key에 해당하는 객체 삭제 |
| Object replace(Object key, Object value) | 지정된 key에 해당하는 객체 value 변경 |
| boolean replace(Object key, Object oldValue, Object newValue) | 지정된 key에 해당하는 객체 value, newValue로 변경 |
| Set entrySet() | 키-값쌍으로 이루어진 Set 반환 |
| Set keySet() | key값만 가져옴 |
| Collection values() | 값들만 가져옴 |
| Object get(Object key) | 키에 해당하는 값 반환 |
| Object getOrDefault(Object key, Object defaultValue) | 키에 해당하는 값이 없으면 지정된 defaultValue 반환 |
| boolean containsKey(Object key) | 지정된 키가 존재하는지 확인 |
| boolean containsValue(Object value) | 지정된 값이 존재하는지 확인 |
| int size() | 저장되어 있는 객체 갯수 반환 |
| boolean isEmpty() | 비어있는지 확인 |
| void clear() | 모두 삭제 |
| Object clone() | 복제 |
ch 11-52~56 Collections 클래스, Collection 클래스 요약
1. Collections
Objects, Arrays, Collections 모두 유용한 메서드(static)을 제공하는 클래스
2. 채우기, 복사, 정렬, 검색
채우기 fill(), 복사 copy(), 정렬 sort(), 검색 binarySearch() 등 제공
3. 동기화 컬렉션 만들기 synchronizedXXXX()
신버전들은 동기화안됨(HashMap, ArrayList 등), 동기화가 필요할 때 사용
List syncList = Collections.syncronizedList(new ArrayList(...));
// ArrayList 동기화 안된 list, syncList 동기화된 list
// syncList는 vector클래스 사용한 것과 동일
3. 변경불가 컬렉션 만들기(읽기전용 readOnly) unmodifiableXXXXX()
static Collection unmodifiableCollection(Collection c)
static List unmodifiableList(List l) 등
4. 싱글톤 컬렉션 만들기 singletonXXXX()
객체 1개만 저장
static List singletonList(Object o)
static Set singleton(Object o)
static Map singletonMap(Object key, Object value)
5. 한 종류의 객체만 저장하는 컬렉션 만들기 checkedXXXX()
static Collection checkedCollection(Collection c, Class type)
static Map checkedMap(Map m, Class keyType, Class valueType)
static Queue checkedQueue(Queue q, Class type) 등
→ jdk 1.5 이후 지네릭스 한가지 객체만 저장가능하게함, 이전 버전은 checkedXXX()이용해 한가지만 저장가능하게 만듦
6. 컬렉션 클래스 요약
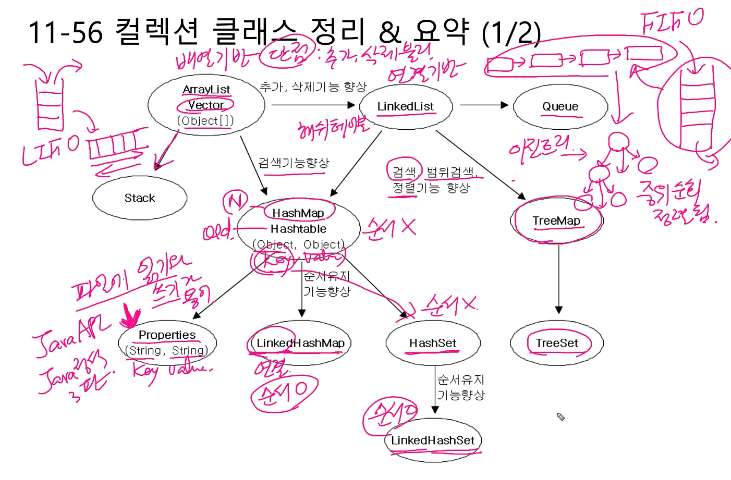
'정리 > Java' 카테고리의 다른 글
| 자바의 정석 142~147강 ch12 지네릭스, 열거형, 애너테이션(2) (1) | 2023.09.16 |
|---|---|
| 자바의 정석 135~141강 ch12 지네릭스, 열거형, 애너테이션(1) (0) | 2023.09.12 |
| 자바의 정석 119~126강 ch11 컬렉션 프레임웍(1) (0) | 2023.09.04 |
| 자바의 정석 연습문제 ch 9 java.lang 패키지와 유용한 클래스 (3) | 2023.09.03 |
| 자바의 정석 연습문제 ch 8 예외처리 (1) | 2023.08.31 |